Microsoft Fabric OneLake: De OneDrive voor data

Elk vakgebied kent het wel: Het werkjargon waar je dagelijks mee om je oren wordt gegooid. Hoe vaak staat een collega naast je om even samen te sparren of te klankborden? De termen scrum en agile lijken door de gangen van ieder bedrijf te zweven en dan heb ik het nog niet eens gehad over de afkortingen die generatie-specifiek zijn. Kladiladi jij bijvoorbeeld meteen het weekend in of ga jij eerst nog langs de vrijmibo voor een lauw biertje? Het is bijna niet bij te houden.
Door: Lotte Oudejans
Wat heeft dit echter te maken met het onderwerp van de blogpost van vandaag? Ik ben blij dat je het vraagt!
Binnen de wereld van IT gaan de veranderingen snel en met nieuwe ontwikkelingen ontstaan ook nieuwe termen. Binnen het Microsoft-landschap is dit niet anders. Met de komst van Microsoft Fabric zijn er veel nieuwe termen bijgekomen, waarbij OneLake misschien wel de belangrijkste is. In dit blogpost wil ik dieper ingaan op de betekenis van deze nieuwe term en de impact die OneLake heeft op de wereld van data.
Het EénMeer
We hebben in juni een Fabric event gehouden bij BusinessBase waarbij mijn collega Timo Bax en ik een presentatie gaven over alle facetten van Microsoft Fabric. OneLake was hier een belangrijk onderdeel van. OneLake wordt omschreven als de storage-laag onder Microsoft Fabric. Je kunt Microsoft Fabric dan ook niet los zien van OneLake. Met het opzetten van iedere Microsoft Fabric omgeving, wordt ook automatisch OneLake geleverd. Het één kan niet zonder het ander.
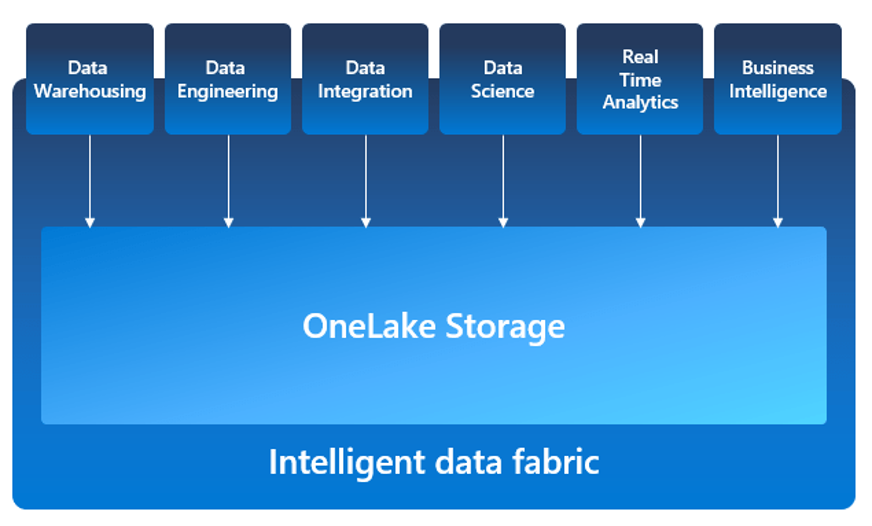
Wil je meer weten over de verschillende Microsoft Fabric componenten bovenop OneLake, zoals Data Engineering of Data Science, lees dan mijn vorige Fabric blogpost of stuur mij een berichtje.
Om dit aspect voor iedereen toegankelijk te maken, wordt OneLake vaak omschreven als de OneDrive voor data (weer zo’n geweldige term). OneDrive is bij velen bekend als de cloudopslag van Microsoft: Het is een plek om al je documenten, foto’s of video’s op te slaan zodat deze geen opslag meer op je eigen laptop of telefoon in beslag nemen en via ieder device met toegang tot OneDrive toegankelijk zijn. Je hoeft je documenten nog maar op één plek te beheren.
OneLake levert hetzelfde: Eén plek voor al je data, die via verschillende plekken toegankelijk is. Dit verklaart de term één, maar waarom meer?
Het EénMeer
Het is eigenlijk heel mooi hoe het woord meer in het Nederlands twee betekenissen kan hebben. We hebben het namelijk bij OneLake niet alleen over het meer waar je in kunt zwemmen, maar ook de vele voordelen, of de meerwaarde, die OneLake kan opleveren. Het idee van een lake is in de datawereld niet nieuw. De term datalake bestaat al veel langer. De gedachte achter data was altijd dat deze gestructureerd moet zijn voordat de data meerwaarde op kan leveren. Maar, vaak is data verspreid en soms zelfs chaotisch. Het idee van een datalake ontstond daarom als een bron waarin alle data samen gegooid mag worden. Er zijn geen limieten of eisen waaraan de data moet voldoen, meer data was in dit geval juist beter. In dit gigantische meer van data, was het vervolgens aan de data-engineer om al deze data gestructureerd samen te brengen.
Met OneLake is dit laatste aspect juist een stuk makkelijker gemaakt. OneLake maakt het mogelijk om al je databronnen te koppelen en op één plek samen te brengen én zet de data vast in één formaat voor je klaar zodat jij direct met de data aan de slag kunt. Eén datameer waarbij de onderliggende structuur universeel is.
De OneLake Shortcuts
We hebben het in dit geval niet over de CTRL-C en CTRL-V shortcuts die je waarschijnlijk dagelijks gebruikt. Binnen OneLake heeft de term shortcuts een nieuwe betekenis gekregen. Denk hierbij meer aan de shortcuts die je op je bureaublad hebt staan voor al je favoriete bestanden en applicaties.
We hebben al gezien dat OneLake het mogelijk maakt je data op één plek samen te brengen, maar hoe werkt dit precies?
Het is uiteraard mogelijk je databron in OneLake te kopiëren, maar wat als de brondata wijzigt? De tijd van handmatige imports ligt hopelijk voor iedereen al lang in het verleden. Shortcuts is één van de manieren binnen OneLake om data in het meer toe te voegen zonder meerdere kopieën te hoeven creëren. Een shortcut is namelijk niets meer dan een verwijzing naar je databron. Via de shortcut kun je aangeven welke databron aan OneLake verbonden moet worden en vervolgens wordt er binnen OneLake een verwijzing naar deze data opgezet. Iedere keer als de shortcut geopend wordt, zie je direct de data uit de verbonden databron.
Op dit moment kunnen Dataverse, ADLS GEN2 storage accounts, Amazon S3 accounts en Google Cloud Storage gemakkelijk via shortcuts gekoppeld worden. Het is zelfs mogelijk een shortcut op te zetten binnen OneLake om ook kopieën binnen je OneLake-laag zoveel mogelijk te voorkomen.
OneLake Mirroring
Een tweede methode waarbij OneLake koppelingen met data mogelijk maakt, is mirroring. Deze term bestaat al veel langer. Database mirroring wordt gebruikt om een backup van een databron bij te houden zodat er altijd een andere kopie van de data beschikbaar is in geval van een storing. OneLake mirroring werkt in principe hetzelfde, maar heeft een ander doel.
Binnen OneLake is mirroring niet bedoeld als backup van een database, maar wordt de methode gebruikt om data binnen OneLake en de gekoppelde databron gelijk te houden voor verdere verwerking of analyse. Mirroring maakt het mogelijk om een beveiligde connectie op te zetten met je databron en daarna worden deze bronnen automatisch gelijk gehouden. Er loopt een constante synchronisatie tussen de data waar je zelf niets voor hoeft te doen.
Met mirroring is het bijvoorbeeld mogelijk Azure SQL DB, Snowflake, of Azure Cosmos DB te koppelen aan OneLake. Binnen OneLake kun je de optie voor mirroring overigens aan- of uitzetten voor de gehele organisatie.
Tot slot
OneLake is de uniforme storage-laag onder Microsoft Fabric waarbij er verschillende mogelijkheden zijn om de data met OneLake te koppelen. Doordat OneLake alle data direct in één formaat samenbrengt, wordt ook de verdere verwerking van de data een stuk toegankelijker. Via shortcuts en mirroring ligt de focus op het creëren van directe koppelingen met je databronnen zodat er maar één kopie van de data ontstaat die altijd up-to-date is. Toch blijft de vraag altijd interessant: Is OneLake wel echt één kopie? En willen we eigenlijk maar één kopie van de data hebben? De medaillon-structuur die binnen het datalandschap zo populair is, heeft toch echt op iedere laag een kopie van dezelfde data staan. Voor nu is dit teveel om verder op in te gaan, maar wellicht voor een volgende blogpost?



